GPT Image 1.5 Prompt Guide
GPT Image 1.5 Prompt Guide connects write prompts for GPT Image 1.5 to a curated English SEO page with model notes, prompt patterns, FAQ coverage, real examples, and related internal links.
Editorially reviewed by GPT Images for prompt usefulness, internal links, FAQ coverage, and source-aware model context.
What this model guide covers
GPT Image 1.5 Prompt Guide is designed for creators comparing image model behavior and prompt formats. It targets the intent to write prompts for GPT Image 1.5, but the page avoids thin keyword stuffing by connecting the topic to prompt structure, real prompt examples, internal links, and FAQ answers.
The practical goal is simple: help someone understand what to write next. The page explains how GPT Image 1.5 prompts should define subject, constraints, references, style, and output checks before a model or generator is blamed for a weak result.
- Use this model guide when the search intent is "write prompts for GPT Image 1.5" and the visitor needs examples before writing from scratch.
- Choose it when GPT Image 1.5 work requires visible constraints such as subject, angle, lighting, composition, text, aspect ratio, or editing target.
- Use the real prompt examples below to see how other prompts structure the same problem, then adapt one variable at a time.
- Keep it as an internal link target for related prompt collections so users can move from broad discovery into specific prompt pages.
Recommended GPT Image 1.5 workflow
translate a model name into practical prompt choices without inventing fragile capability claims. A good workflow should be repeatable, inspectable, and easy to adapt across tools. The same prompt can behave differently in GPT-IMAGE-2, Nano Banana 2, Stable Diffusion, Midjourney, Jimeng AI, or a local ComfyUI setup, so this page keeps the reusable structure separate from tool-specific adjustments.
- Start by defining the job: what the image must communicate, where it will be used, and what failure would make the result unusable.
- Translate the job into a prompt skeleton for GPT Image 1.5: subject, scene, medium, camera or composition, style constraints, and output constraints.
- Pick one example prompt from this page and copy only the structure that matches the job; avoid copying decorative phrases that do not serve the image.
- Run a first generation, then change one variable at a time: framing, lighting, color palette, reference strength, text content, or background density.
- Save the winning prompt with notes about model, tool, aspect ratio, and any reference images so the pattern can be reused later.
- separate subject, composition, reference handling, typography, and iteration notes
Quality checks before publishing
Before using a generated image in production, review the output against the original job. The best prompt is not the longest prompt; it is the prompt that makes the model spend attention on the details that matter.
- GPT Image 1.5 should have a clear subject and a visible hierarchy; if the prompt gives equal weight to every detail, the image often becomes noisy.
- The prompt should separate content from style, especially when moving between GPT-IMAGE-2, Nano Banana 2, Stable Diffusion, Midjourney, or other image models.
- If the output needs readable text, keep the phrase short, quote it exactly, and verify the final image rather than assuming the model handled typography perfectly.
- If the output must match a brand, character, room, product, or reference image, name the fixed traits and describe what is allowed to change.
- Avoid stacking too many model-specific shortcuts on a reusable prompt page; keep the main prompt portable, then add model notes as a final layer.
- Review whether the page sends visitors to deeper prompt examples, related use cases, and FAQ answers instead of trapping them in a generic SEO article.
Common mistakes to avoid
Most failed image generations are not caused by a missing magic word. They usually come from unclear hierarchy, mixed intent, unsupported text requirements, or a prompt that asks for too many changes at once.
- Writing a GPT Image 1.5 prompt as a pile of keywords without a production goal.
- Changing model, tool, aspect ratio, and reference image at the same time, which makes it impossible to learn what improved the output.
- Using vague quality words such as beautiful or professional without defining the visible evidence of quality.
- Ignoring downstream use, such as ecommerce crop safety, ad text legibility, app store screenshots, or poster readability.
- Treating GPT Image 1.5 Prompt Guide as a final answer instead of a starting point connected to prompt examples and iteration notes.
GPT Image 1.5 prompt patterns
Production brief prompt
Create a GPT Image 1.5 image for [audience] that communicates [message]. Main subject: [subject]. Scene: [setting]. Composition: [camera angle, crop, spacing]. Style: [medium, lighting, color direction]. Constraints: [aspect ratio, readable text, brand colors, negative space]. Avoid: [visual mistakes, clutter, wrong mood].
It separates the job, subject, scene, style, and constraints, which makes the prompt easier to test across different image models.
Reference-aware prompt
Using the reference as the fixed source of truth, generate a GPT Image 1.5 variation. Preserve [identity traits, product shape, logo placement, character features, room layout]. Change only [background, lighting, camera angle, outfit, color palette]. Keep the output consistent with [use case] and do not invent extra objects.
It tells the model what is fixed and what can change, which is critical for image editing, character consistency, product shots, and brand work.
Iteration prompt
Revise the previous GPT Image 1.5 result by improving [one problem]. Keep [successful elements] unchanged. Adjust [single variable] to [specific direction]. The final image should feel [desired mood] and remain suitable for [placement or channel]. Do not change [protected details].
It controls iteration by changing one variable at a time, so you can learn which instruction improved or damaged the output.
Model transfer prompt
Rewrite this GPT Image 1.5 prompt for [target model or tool]. Keep the core subject, composition, and constraints. Convert unsupported syntax into natural language. Add model-specific notes only at the end: [aspect ratio, style strength, reference strength, negative prompt, seed, or typography instruction].
It preserves the creative brief while allowing each model or tool to receive the instructions in a format it can use.
Prompt examples for GPT Image 1.5
These examples are selected from the current English prompt catalog so the page links visitors into real prompt detail pages instead of stopping at generic advice.
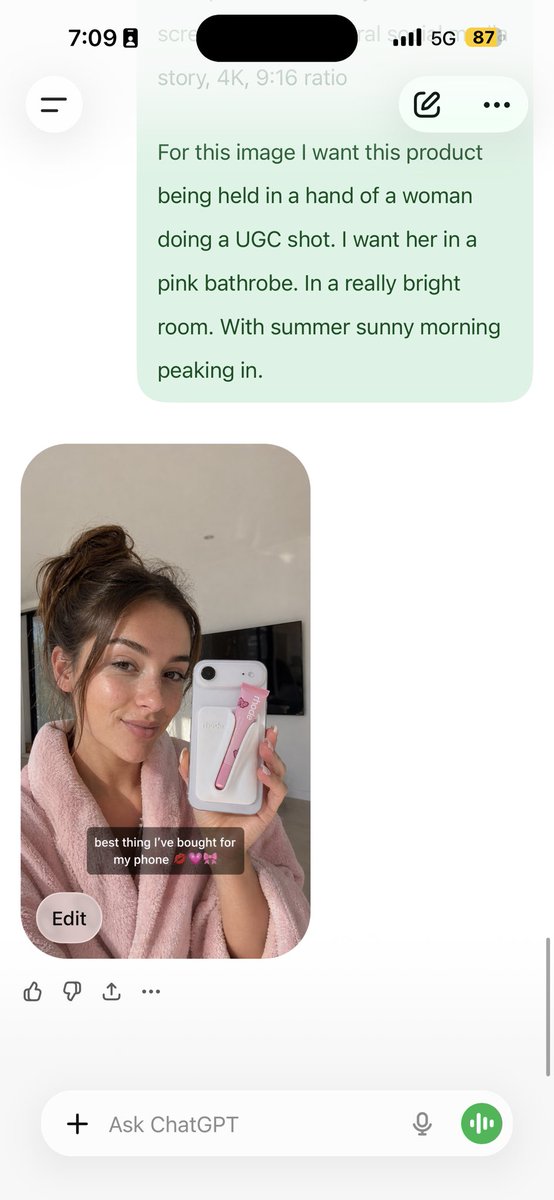
analyze this photo and give me a detailed JSON prompt that recreates it. brea...
analyze this photo and give me a detailed JSON prompt that recreates it. break down the color grading and every exact color in the photo (use Opus, not Sonnet. Opus has stronger visual analysis and writes more detailed JSON) paste that JSON into ChatGPT upload your product image and prompt: using this JSON as reference, generate a person holding my product save that generated photo as your character reference attach it to every future generation for facial consistency you now have a consistent UGC model that works across any product the JSON controls the lighting and color grading. GPT image-2 handles the character. you control the product placement. the #1 tell on AI photos is flat colors and a grainy look. this method removes both. 5 minutes to set up. unlimited variations after.

YouTube Thumbnail - Japanese GPT Image2 Thumbnail
{"type":"Japanese YouTube thumbnail collage","style":"bold anime-tech promotional thumbnail with clean digital illustration, high contrast, saturated colors, thick outlined typography, energetic magazine-style composition","canvas":{"aspect_ratio":"16:9","resolution":"1200x630"},"background":{"frame":"mint green outer border with cyan accent strip along the top and bottom edges","main_scene":"warm modern bedroom interior with wooden headboard, beige bedding, cream curtains, bedside shelf, and a small alarm clock"},"layout":{"sections":[{"title":"データセット作り!","position":"top-left","count":8,"labels":["back view","three-quarter back view","front view","full back standing view","side profile","rear side profile","three-quarter front view","standing portrait with crossed arms"]},{"title":"部分修正!","position":"bottom-left","count":1,"labels":["character editing app screenshot with anime woman in white jacket over blue shirt"]},{"title":"素材作り!","position":"lower-mid-left","count":1,"labels":["smartphone asset design image showing a hand holding a purple screen phone with a large eye symbol and a vertical strip of 5 small variant thumbnails"]},{"title":"合成!","position":"upper-center-right","count":2,"labels":["anime woman cutout portrait","bedroom background plate"]}],"connectors":{"count":2,"style":"curved pink arrows with white outline pointing from the cutout portrait and bedroom plate toward the final composite on the right"},"text_overlays":{"count":7,"items":["データセット作り!","部分修正!","素材作り!","合成!","「{argument name=\"headline text\" default=\"GPT Image2\"}」徹底検証!","ノイズ除去法から{argument name=\"feature text\" default=\"LoRA学習\"}まで","©{argument name=\"credit name\" default=\"スタジオ真榊\"}"]}},"subjects":{"main":{"type":"anime woman","count":1,"appearance":{"age":"young adult","build":"slim curvy","hair":{"color":"{argument name=\"hair color\" default=\"long black\"}","style":"very long straight hair with soft shine, center part, strands falling over shoulders"},"face":"intentionally blurred/censored rectangle over the face","outfit":["white fitted long-sleeve scoop-neck top","visible black camisole straps","black pants"]},"pose":"seated on the edge of a bed, torso angled slightly left, hands resting near lap, looking toward camera"},"inset_character":{"type":"same anime woman reference art","count":10,"notes":"all inset figures use the same character design with face blurred in several panels"}},"typography":{"primary":"very large Japanese headline across the bottom in white with black outline and hot pink emphasis around GPT Image2","secondary":"subheadline in orange, white, black, and bright blue mixed emphasis","annotation":"handwritten energetic pink labels with white stroke near each inset section"},"color_palette":{"count":8,"colors":["hot pink","white","black","cyan","mint green","orange","beige","dark brown"]},"composition":"right half dominated by the final anime bedroom illustration, left half packed with inset process examples and screenshots, oversized bottom headline spanning nearly full width, designed to advertise a deep-dive verification article about GPT Image2 workflows for dataset creation, partial edits, asset generation, compositing, noise removal, and LoRA training"}
Infographic / Edu Visual - Automotive poster transformation prompt
Ultra-clean automotive poster featuring the exact same car as the photo that will be provided later. The AI must replicate the car from the uploaded photo with identical body shape, proportions, stance, color, trims, wheels, and all visible exterior details.
The car is presented in a front three-quarter angle facing right, matching the perspective of the original reference layout, but now depicted in a subtle {argument name="action" default="drifting action"}. The drift is expressed through realistic weight transfer, slight body lift, controlled smoke plumes from the rear tires, and faint curved tire marks behind the vehicle, without distorting the original car’s geometry.
Headlights follow the exact style from the reference photo of the car, with optional warm fog lights glowing if the provided car has them. All decals, emblems, plates, and window tints must match the car from the uploaded photo.
The car drifts on a glossy white reflective studio-like floor that maintains soft reflections and realistic shadows, enhanced with light drift skid reflections and directional smudges.
Background remains a clean white-to-light-gray gradient with a giant semi-transparent bold typography of the car model name (auto-extracted from the uploaded photo) vertically dominating the background.
At the very top: clean branding text “{argument name="brand name" default="CAR COMPANY NAME"}” (or the brand detected from the uploaded car photo). Under it, spaced-out stylized tracking text containing the same brand and model name.
Below the car: centered title of the exact model name from the uploaded photo.
Under that, a short descriptive paragraph about the car’s character (efficiency, style, reliability).
Bottom section shows a clean grid layout of specifications. If real specs are known from the detected car model, generate accurate values; if not, generate placeholders in the same layout style (4 columns: horsepower, 0–100 km/h, top speed, engine displacement/fuel type).
Entire poster is minimalist, editorial, high-key studio lighting with ultra-sharp reflections, crisp shadows, modern typography, and 4K believability, blending clean design with dynamic drifting energy, Ratio 9:16![[CORE TASK]
Transform the...](https://raw.githubusercontent.com/freestylefly/awesome-gpt-image-2/main/data/images/case78.jpg)
Image Generation Case Examples
[CORE TASK] Transform the provided input image into a pose-and-light analysis sheet. This is NOT a finished character illustration. This is NOT a clothing sheet. This is NOT a beauty-preserving redraw. This is a white-line rough mannequin conversion. [PRIMARY GOAL] Extract and visualize only: - pose structure - body balance - camera angle - body line flow - inferred light source placement - illuminated areas and light intensity [INPUT ROLE] Use the provided image as the strict anchor for: - pose - camera angle - body tilt - weight distribution - approximate lighting situation Do NOT preserve: - face rendering - hairstyle rendering - clothing detail - accessories - weapon detail - background architecture - character identity - emotional expression [FIGURE CONVERSION] single rough mannequin-like human figure white body contour lines white internal construction lines simple mannequin head no face no eyes no mouth no eyelashes no personality no individual identity human figure should look like: - rough pose mannequin - anatomy proxy - line-based body guide - structural sketch - white-line rough dummy keep: - pose readability - silhouette flow - head tilt - torso direction - pelvis direction - limb placement [BACKGROUND] pure black background negative-style dark field no scenery no props no architecture no environmental storytelling [LINE STYLE] rough white line drawing clean but sketch-like construction-line feeling anatomy guide lines visible joint flow visible body contour emphasized no polished illustration finish [LIGHT ESTIMATION] predict the likely light source positions from the input image visualize the light sources and illuminated areas using green glow only use green light intensity with variation: - strongest green where the light directly hits - medium green for wrap light - soft green for reflected or fading light mark the estimated light sources with labels and arrows such as: - Main Light - Rim Light - Fill Light - Floor Bounce - Back Light only if appropriate IMPORTANT: do not invent random lights infer lighting from the original input image if the lighting is ambiguous, keep the annotations simple and plausible [GREEN LIGHT VISUALIZATION] show green glow on: - head / skull plane - neck - shoulders - chest plane - ribcage direction - pelvis edge - thigh planes - knee contact points - floor contact bounce if applicable use green light not as decoration, but as lighting analysis information [POSE PRIORITY] 1. preserve pose structure 2. preserve camera angle 3. preserve body balance 4. preserve head-torso relationship 5. visualize likely light direction 6. show illuminated areas with readable green intensity variation [NEGATIVE] finished person, cute girl, detailed face, hair rendering, clothing rendering, weapon emphasis, beautiful anatomy

Infographic / Edu Visual - Underwater Forest Stream Photography
Shot with a high-definition underwater camera, this prompt captures real underwater natural scenery in a {argument name="environment description" default="clear shallow stream next to a tropical primeval forest"}.
Vertical composition, 3:4 aspect ratio, medium-to-long shot. The lens is slightly below the water surface, showing the shimmering bottom of the water surface above with realistic water wave refraction and natural reflections.
Sunlight shines diagonally into the water from the top right, forming soft beams and underwater spots. Dark reflections and shadows of large tree branches occupy part of the composition in the upper right.
In the middle is clear and quiet stream water with slight suspended particles and {argument name="number of fish" default="5-8"} native freshwater small fish swimming naturally, mainly gray-silver and light brown, varying in size and distance, not forming an organized school. On the stream bed, deep green, yellow-green, and brownish-green water plants grow naturally, swaying gently with the current, distributed naturally unlike an artificial aquarium.
The bottom consists of gray-brown fine sand, gravel, pebbles, and several naturally shaped stones with slight algae marks and signs of water erosion. Multiple springs at the bottom show fine sand billowing slowly from small holes, creating light sand clouds and local water disturbances, not white smoke, steam, or large bubbles.
Natural landscape live-action photography, high-end natural documentary feel, close to National Geographic ecological photography. Features transparent water, natural lighting, restrained colors, realistic underwater optical effects, slight graininess, natural depth of field, and high-definition details.
No people, no buildings, no artificial traces, no text, no borders, no LOGO. Avoid CG feel, aquarium look, seabed coral, exaggerated fish schools, oversaturated greens, dreamy lighting effects, or plastic water plants.
Infographic / Edu Visual - Nigerian Street Eats Collage
{"type":"vibrant Nigerian street food collage poster","format":"vertical editorial travel-food montage","style":"high-contrast cinematic night photography mixed with hand-painted street poster typography, smoky atmosphere, saturated neon colors, gritty documentary realism, white comic-panel borders, yellow brush lettering, handwritten annotation arrows","main_title":{"text":"{argument name=\"main title\" default=\"NIGERIAN STREET EATS\"}","position":"left-center over main grill scene","typography":"large distressed white block letters for first word, oversized yellow brush-script words below"},"subtitle":{"text":"{argument name=\"subtitle text\" default=\"HOT & FRESH\"}","position":"under main title on red paint-stroke banner","typography":"condensed white uppercase letters"},"scene":{"location":"busy Lagos night market street with food stalls, crowds, headlights, neon signs, smoke, open flames, and warm work lamps","mood":"energetic, smoky, late-night, authentic street-food adventure","lighting":"dramatic orange firelight and grill glow contrasted with blue-green neon and dark urban background"},"central_panel":{"position":"top-left and center, largest panel","description":"street vendor grilling many skewers of spicy suya over open charcoal flames; vendor wears dark cap, grey shirt, black apron, and black gloves; face obscured by shadow; smoke curls around the meat; yellow bus and neon food stall sign in background","visible_signs":["SUYA","PEPPER SOUP"],"apron_text":"SADA SUYA"},"panels":{"total_count":13,"items":[{"label":"main suya grill hero panel","position":"upper-left to center","content":"vendor tending rows of suya skewers over glowing charcoal, with the large poster title overlay"},{"label":"SMOKY SUYA NIGHTS","position":"top-right","content":"close-up of heavily seasoned suya skewers on a grill, smoke rising, handwritten white and yellow label with arrow"},{"label":"LAGOS AFTER DARK","position":"right-middle","content":"wide night street-market scene with umbrellas, food stalls, traffic lights, crowds, and city buildings"},{"label":"SUYA SPICE","position":"middle-left","content":"hands sprinkling orange-red spice over raw marinated meat, white arrow pointing to seasoning"},{"label":"PUFF-PUFF IN PROGRESS","position":"middle-center","content":"round golden puff-puff dough balls frying in bubbling oil, one lifted in a wire skimmer"},{"label":"CORN & UBE","position":"middle-right","content":"grilled yellow corn cobs beside round greenish-brown African pears, with arrow label"},{"label":"SMOKY JOLLOF","position":"lower-left","content":"foil trays filled with reddish jollof rice, steam and smoke drifting upward"},{"label":"AKARA VIBES","position":"lower-center","content":"golden bean cakes frying in a deep pan of hot oil, arrow label"},{"label":"SHAWARMA STATION","position":"lower-right","content":"gloved hands holding an open wrap stuffed with meat, cabbage, carrots, and sauces being drizzled from squeeze bottles"},{"label":"PEPPER SAUCE & ONIONS","position":"bottom-left","content":"metal trays of sliced red onions, bright red pepper sauce, and green sauce at a condiment station"},{"label":"GRILLING GOODNESS","position":"bottom-center","content":"many skewers grilling over flames and smoke, close-up of charred meat with orange fire glow"},{"label":"PUFF-PUFF DOUGH","position":"bottom-right","content":"large green bowl and smaller pot filled with pale dough pieces or batter, arrow pointing to dough"},{"label":"neon slogan sign","position":"bottom-right corner","content":"glowing red, green, and white neon sign with crown doodle reading NA FOOD WE-DEY CHASE"}]},"footer":{"text":"{argument name=\"footer slogan\" default=\"REAL FLAVOUR. REAL PEOPLE. REAL LAGOS.\"}","position":"bottom across yellow paint-stroke strip","typography":"black handwritten uppercase text"},"color_palette":"charcoal black, flame orange, spice red, neon green, electric cyan, warm yellow, smoky grey, white panel borders","composition":"dense magazine-cover collage with tilted rectangular panels separated by thick white borders; main hero image dominates, supporting food close-ups arranged around it; handwritten labels and arrows add street-guide energy","rendering_instructions":"make it look like a finished food-tour poster, not a flat infographic; include realistic steam, oil bubbles, smoke, glowing coals, busy market depth, gritty textures, and legible stylized English labels","negative_prompt":"no clean studio background, no empty panels, no minimalist layout, no washed-out colors, no generic Western fast food, no misspelled main title"}
Infographic / Edu Visual - Instructional dance poster prompt
Create a clean, black-and-white instructional poster showing a {argument name="steps" default="16-step"} dance sequence performed by a single {argument name="dancer" default="female dancer"}.
Layout:
4x4 grid (16 panels total)
Each panel shows the same dancer in a different pose
Full-body, centered in each frame
Even spacing, consistent framing across all panels
Dancer:
Female, long flowing hair
Wearing a fitted, reflective/sequined crop top and long flared skirt
Elegant, confident, expressive poses inspired by {argument name="dance style" default="vogue and waacking"} dance styles
Panel Details:
Each panel has a bold number (1–16) and a short title at the top (e.g., “WATER CALL,” “LIQUID RISE,” “VOGUE FRAME,” etc.)
Include small instructional captions at the bottom of each panel
Add subtle arrows and motion lines to show movement direction (arms, hips, body flow)
Style:
Black and white (monochrome)
High contrast, sharp studio lighting
Fashion editorial photography look
Clean white or light gray background
Modern sans-serif typography
Overall Feel:
Minimalist, polished, magazine-quality layout
Smooth progression of movement across all 16 frames
Dynamic but clean, easy-to-follow instructional design
Infographic / Edu Visual - Premium Korean Palm Reading Guide
Create a premium Korean palm reading guide image based on the uploaded palm photo. All visible text in the final image must be Korean only. Use clean Korean sans-serif typography. The title must be exactly “손금 분석 가이드”. Create a refined two-panel layout: Left panel: place the uploaded real palm photo inside a clean rounded card. Preserve the original hand shape, palm lines, skin texture, and natural details. Do not distort or redraw the hand. Right panel: create a separate black-and-white palm contour interpretation diagram based on the same hand. Highlight the main palm lines with thin precise lines and label them in Korean. Include Korean labels and sections: “손금 분석 가이드”, “전체 요약”, “생명선”, “두뇌선”, “감정선”, “운명선”, “재물선”, “태양선”, “결혼선”, “성격”, “직업운”, “재물운”, “연애운”, “조언”, “확인 불가”. Analyze palm shape, finger proportions, life line, head line, heart line, fate line, wealth line, sun line, marriage line, line depth, length, direction, breaks, branches, and overlaps. If something is unclear, write “확인 불가”. Keep the Korean interpretation short, realistic, calm, and advisory. Design style: 1:1 square format, white background, black and warm dark gray text, thin hairline dividers, rounded cards, subtle shadows, large margins, generous negative space, precise grid, minimal line pictograms, luxury editorial report, high-end wellness analysis, elegant and expensive-looking. No English text, no roman letters, no broken Korean, no random glyphs, no colorful decoration, no cartoon style, no occult symbols, no tarot imagery, no horror mood, no messy background, no watermark.
Related prompt guides and libraries
FAQ about GPT Image 1.5
How do I use GPT Image 1.5 prompts from gptimages.dev?
Start with the examples that match your visual job, then copy the prompt structure rather than copying every adjective. Replace the subject, scene, channel, aspect ratio, and constraints with your own details. If the first result is close, keep the successful parts fixed and change one variable at a time. This makes the page useful as a prompt library, not just a keyword page.
What is the best prompt format for GPT Image 1.5?
A dependable format is brief first, details second, checks last: describe the image goal, then the subject, scene, composition, style, reference rules, and output constraints. For models such as GPT-IMAGE-2, Nano Banana 2, Stable Diffusion, Midjourney, or Jimeng AI, keep the core prompt portable and add tool-specific settings only when the interface supports them.
Can I reuse these prompts across different AI image models?
Yes, but reuse the structure more than the exact syntax. A prompt that works in one generator may need different wording, reference strength, aspect ratio settings, or negative prompts in another. The safest workflow is to preserve the creative brief, then adapt only the model-specific layer after you inspect the first output.
How should I collect the best AI image prompts?
Save prompts with the final image, model or tool name, aspect ratio, reference images, and a short note explaining why the result worked. Group them by use case such as product photography, character consistency, UI mockups, posters, logos, or text-in-image prompts. That collection becomes much more useful than a flat list of attractive phrases.
Why do GPT Image 1.5 prompts fail?
Common causes include unclear subject hierarchy, too many styles in one prompt, vague quality words, unsupported text requirements, missing reference rules, and uncontrolled iteration. Fix the prompt by naming the production goal, protecting the details that cannot change, and testing one adjustment per generation instead of rewriting the whole prompt every time.
Are these prompt examples enough for commercial work?
They are a starting point, not legal or brand clearance. For commercial work, check the terms of the model or generator, review rights for reference images, verify text and logos manually, and keep a record of the prompt, source assets, and final edits. The page helps with prompt quality, while usage rights still depend on your workflow and provider terms.